
Home | Biodata | Biography | Photo Gallery | Publications | Tributes
Indus Script

|
|
Home | Biodata | Biography | Photo Gallery | Publications | Tributes Indus Script |
|
| Writing on the blackboard in the faculty room of the Department of Statistics by Dr.Gift Siromoney on December 10, 1987 is still there. | |

| 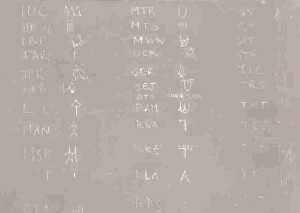
|
In 1968, Prof. Gift Siromoney presented a paper on "Context-sensitive rules in Tolkappiam" in the Second World Tamil Conference, held at Madras. In the same conference, Mr Iravatham Mahadevan presented his landmark paper entitled "Dravidian parallels in Proto-Indian Script". They met and became friends. Later Mr Mahadevan compiled a comprehensive computerized concordance [*] of the Indus script. When he presented a copy of the Concordance to Dr GS, he was naturally attracted to this puzzling script. His work with Prof. (Mrs). Siromoney and others on cryptography added further impetus. It was a happy day for me, when he invited me to join him in his response [1] to what Prof. Asko Parpola, an international authority on the subject, described as "the major challenge of the century" -- the challenge of deciphering the Indus script.
Indus Valley Civilization was one of the largest in the ancient world. Also known as Harappan civilization, it flourished along the course of the Indus river during 2600-1900 B.C. We have no authentic information on the language that the Harappans spoke, the race that they belonged to or the names of kings who ruled them. The only clue is to be found in the corpus of inscriptions in a pictographic script that they have left behind. The studies listed in the publications here are concerned with a computer-oriented structural analysis of this script. They are based on the texts and tables provided by Mr Mahadevan in his Concordance.
One of the basic problems in the study of the Indus script is the determination of the grammatical class that each sign belongs to. If two signs are syntactically equivalent, we can expect them to exhibit similar positional characteristics. Making use of MacQueen's k-means algorithm, the common Indus signs are classified into homogeneous subgroups [3].
It is worth noting that the positional statistics of the signs are obtained on the assumption that each line of an Indus text represents a complete sentence. In the case of some long texts at least, this assumption may not be valid. Thus there is a need for an objective procedure to test whether a line of text can be regarded as consisting of more than one sentence and, if so, to obtain the constituent segments. We have demonstrated that dynamic programming approach to the problem of segmentation yields interesting results [4,11].
There is another kind of segmentation that the scholars are working on. It is concerned with segmenting a single text into its constituent parts. In particular, scholars are interested in studying the association between signs occurring next to each other [6]. It is also of interest to study signs that occur in the same inscriptions, since they share a common context [1]. Furthermore, there is a need to study each Indus sign with reference to its archaeological contexts of occurrence such as the site at which it is found [7] , the object on which it is inscribed [8] and the field symbol it is associated with [9]. It can provide valuable clues to the purpose/meaning of a sign. Drawing ideas from the analysis of categorical data, we have defined an index of affinity/antiaffinity to measure the association and an analytical procedure to interpret the measure thus obtained [5]. Characteristics of sequences that occur frequently have also been investigated with reference to the different metropolitan centres of the civilization [2].
The structural analysis reported in these studies can be utilized for many useful applications. One such application is the generation of "texts" which display Harappan features [1]. Three models are presented for this purpose. The models can also be used to isolate "negative" strings whose structure is definitely non-Harappan. Taken together, these strings can be used to infer a grammar for the Harappan language.
It is expected that studies of this nature will lead to a greater understanding of the structure of the Harappan language and stimulate further research. The decipherment
per se is still very much in the realm of speculation. Although many claims have been made, there is no convincing decipherment generally acceptable to the scholars. Dr Siromoney's plan was to get to know the structure of the texts well, before any attempt to decipher the script was made. We couldn't get around to do the second part of the work. So the challenge still remains.
[*] The Indus Script: Texts, Concordance and Tables, Memoirs of Archaeological Survey of India, No. 77, New Delhi, 1977
-Abdul Huq, Department of Statistics, Madras Christian College, Tambaram, Chennai 600059.
Publications