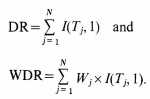Home | Biodata | Biography | Photo Gallery | Publications | Tributes
Epigraphy

|
|
Home | Biodata | Biography | Photo Gallery | Publications | Tributes Epigraphy |
|
1. Introduction
Tamil is one of the national languages of the Indian Union and it is the official language of the State of Tamil Nadu, whose capital is Madras city on the eastern coast of South India. The Tamil language is spoken by about fifty million people, some of whom live in Sri Lanka, Malaysia and Singapore. As one of the ancient languages of India, Tamil has a history of more than two thousand years, and a literature comparable to the best in the world. Its earliest written records go back to about the third century B.C. and the modern script has gradually evolved from this ancient script known as Tamil-Brahmi (Siromoney 1982).
During the medieval period, from the tenth to the thirteenth centuries, tens of thousands of Tamil inscriptions were carved on stone walls of temples (Fig. 1) and many copper-plate charters were issued by ruling monarchs. Some of the inscriptions of this period have been discovered as far away as Burma and Southern China, where merchant guilds had established trading posts. South India is also well known for its rich sculptural treasures, stone carvings, bronze images and paintings (Siromoney, Bagavandas and Govindaraju, 1980).
A few projects linking Indian epigraphy with the latest computer technology have been proposed and implemented with a fairly high degree of success. Of special interest are the techniques of image enhancement and information retrieval. It has been demonstrated that image enhancement could be used for reading inscriptions (Siromoney, 1975). A statistical analysis of personal names in ancient Indian inscriptions has been reported in the recent years (Karashima and Subbarayalu, 1976). In addition, computer recognition of ancient and medieval Indian scripts has been reported (Chandrasekaran, 1982). Once the scripts in inscriptions are recognized, then texts can be recorded and the inscriptions can also be assigned appropriate dates. Computer techniques may be used to assign approximate dates to inscriptions of unknown authorship from medieval Tamil inscriptions found in the southern part of India (Siromoney, Chandrasekaran and Chandrasekaran, 1981).

Fig. 1. A sample of a medieval Tamil inscription. The letters are cut deep in hard stone. However, they appear as though they are embossed and this special effect is obtained by a side-lit photographic method specially devised by us for copying inscriptions.
For those inscriptions which are difficult to date, the present methods of assigning probable dates are based primarily on expert opinion. We are fortunate to have in India experts who have studied carefully a large number of inscriptions and are able to determine the date of an unknown inscription within a few decades. Apart from general principles, an expert also has to depend on memory and furthermore, to compare a large number of estampages and charts before assigning a date to any given inscription.
2. Nature of the problem
Many inscriptions do not contain enough historical details to fix their authorship conclusively. For instance, for inscriptions with the name Rajaraja, it is not always clear whether Rajaraja the First or the Second or the Third is intended. Some inscriptions have only the king's title such as Ra$ja Ke$sari or Ko$ne$rinmai Konda$n. From these, it is not possible to identify the king, since during the Chola period, if a king had the title Ra$jake$sari, his successor would have the title Parake$sari, whose successor in turn would have the title Ra$jake$sari. The title Ko$ne$rinmai Konda$n was also used by more than one king. To assign dates to such inscriptions and to identify the kings, paleography is the main tool.
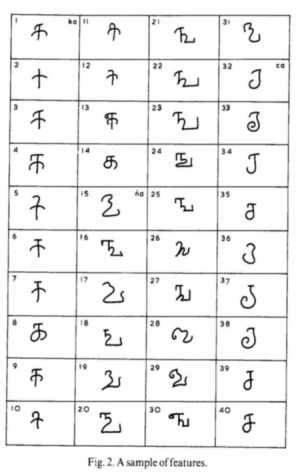
During the period of a single king, inscriptions may have different features for the same characters. For instance, the Rajaraja inscription found at Mahabalipuram belongs to the nail-headed variety whereas the Rajaraja inscription found on the walls of the Brihadiswarar temple at Tanjavur does not conform to this type, even though both the inscriptions belong to the same regnal year of the king (see Fig. 2). It is clear, therefore, that each inscriber had his individual style and there was a good deal of diversity in style in a given period. There was also a certain amount of regional variation. Thus even for the experts, it is difficult to assign dates to many inscriptions, whether complete or fragmentary.
We know that different letters of the Tamil script have undergone changes over the centuries (Siromoney, Govindaraju and Chandrasekaran, 1980). Broadly speaking, during each century each letter was written in a particular style and therefore one can speak of period characteristics of letters in addition to the scribal characteristics within a given period. It is not always easy to decide which is a scribe characteristic and which is a period characteristic.
3. Feature selection
First of all, certain features are selected from each of the authentic inscriptions of known authorship. A feature can be part of a letter or a whole letter. For instance, in the letter ka there may be only a horizontal line at the top. This can be treated as a feature if it is fairly stable within the sample of letters forming the inscription. The feature may also be a small nail-head at the top of the letter ka in the place of the horizontal line. Normally, two features are not included if they are not independent. For example, the horizontal lines on top of ka and sa are not considered to be distinct features. The changes in the letters with respect to various strokes and loops are considered to be the features.
After having listed a number of such features, say, N features, each inscription is encoded as follows. The presence of a feature in the inscription is indicated by a '1' and the absence by a '0'. Thus each sample is represented by a vector of N digits, with the jth position having the value 1 or 0 according as the jth feature is present or absent in the sample. Let us assume that there are M sample inscriptions available. All the feature vectors corresponding to the authentic sample inscriptions are stored in the memory of the computer forming a 'library'. The jth feature of the ith sample in the 'library' is denoted by Lij. A new test inscription, to which we wish to assign a date, is taken up and it is also represented by a vector of N digits. The jth position of this feature vector is indicated by Tj.
A period is taken to be a well defined interval of years. For instance, a period may be a span of 50 years from AD 1001 to 1050. A sample is said to belong to a period if the date of the sample falls within the range of that period.
The feature vector for the period could be obtained by considering the features of the sample inscriptions from that period.
A feature may be reckoned to be present in a given period if it is present in at least one of the inscriptions belonging to that period. Using such a definition, it is possible to represent each period in the form of a feature vector of length N.
In order to compare the feature vectors of the test inscription with those of the library inscriptions, one can make use of a variety of coefficients of similarity (Sokal and Sneath, 1963; Nagel, 1973, 1976; Nagel and Rosenfeld, 1973; Everitt, 1974). We propose, however, simple similarity coefficients that would consider only the matched pairs of features present in both the test and library feature vectors.
4. Direct comparison method
In this method, the feature vector of the test inscription is compared with each of the library feature vectors and similarity values are obtained using a similarity function. The similarity function is defined as
![]()
where Fi is the similarity value of the test inscription and the ith sample in the library.
This similarity function counts the number of matched pairs of ones and ignores the zeroes. In other words, it counts only the number of agreements of the features present. With these similarity values, it is possible to find out that inscription in the library which is closest to the test inscription and hence the corresponding period.
If Fk = maxi{Fi}, then the test inscription is matched with the kth sample in the library and the corresponding period is assigned to it. If this maximum value is attained by more than one sample in the library, then it is indicated in the printout.
5. Weighted comparison method
Sometimes the highest value of similarity measure, being equally shared by more than one library inscription belonging to different periods, may produce a tie. In order to break the tie, a weighted similarity measure is proposed which will have greater discriminatory power. A rare feature of a particular period will have better discriminating capacity than the common features. Hence by giving suitable weights to such features, the similarity values are calculated. Let
Wj denote the weight assigned to the jth feature. Then the similarity function is written as
![]()
where
Gi is the weighted similarity value of the test inscription and the ith sample in the library.
The assignment of the test inscription is as follows.
If Gk = maxi {Gi }, then the inscription is assigned the period to which the kth sample belongs. If there are ties, they are indicated in the printout.
The weights for the features could be assigned according to their relative importance. Hence we suggest two methods of assigning weights to the features which have been used in our experiment.
Method A
If a feature occurs in only one period, then it is considered to be more important for that period compared to another feature which occurs in more than one period. In general, a feature occurring in r periods will behave better than the one which occurs in r+1 periods or r+2 periods and so on. Thus we can assign weights to the features depending upon their respective frequencies.
Let P denote the number of periods under consideration. If we consider features occurring in at the most R (< P) periods and if the jth feature occurs in S periods, then the weight for that feature is assigned as:
W1 j
= R S+1 if S < or = R,
0 otherwise.
S+1 if S < or = R,
0 otherwise.
The maximum weight for any feature cannot exceed R. If a feature is present in all P periods, we discard it, as it has no discriminatory power.
Method B
The next method of assigning weight to a feature is based on the diadic logarithm of the number of occurrences of the feature.
Let us use the same terminology as in method A for R and S. If 2X-1<R<or=2X for some positive integer X, then the assignment of weights is as follows.
If the
jth feature occurs in S periods and if 2Y-1<or=S<2Y for a positive integer Y, then the weight is calculated as
W2 j = X(Y1) if S<R, 1 if S=R, 0 otherwise.
For instance, if R = 40 then X= 6 and hence the weight varies from 1 to 6. If a feature occurs in 10 periods then S = 10 and Y=4 and thus the weight for that feature is 3.
Methods A and B assign greater weights to those features which occur in fewer periods. Apart from these two methods, one may also assign weights using other scales.
The number of features can be reduced by deleting those features which do not have sufficient discriminatory power. But this may lead to an insufficient number of features for comparison, particularly, when the comparison results in a tie.
6. A direct method of assigning a period to a test inscription
In the methods described so far, a test inscription is compared with individual inscriptions stored in the library by giving equal or unequal weights to the features.
An alternative method is proposed to compare a given test inscription directly with features of different periods. The library will now be composed of features of the periods instead of the samples. The jth feature of the ith period is thus denoted by Li j and the value of M is taken to be the number of periods.
The test inscription is assigned to the sth period by the direct comparison method, if Fi is maximum for i=s, and to the tth period by the weighted comparison method, if Gi is maximum for i=t.
This method would work satisfactorily if there are distinct period characteristics for each of the periods chosen. If there are no clear boundaries for the periods of fixed duration, then it may be possible to define periods with varying durations. If a scribe of a particular inscription had lived for a few decades overlapping two periods, an inscription with the same scribal characteristics may be found in both the periods. Thus, if this method is followed, one may have to allow for a variation of certain number of years on either side.
7. An experiment
In order to implement the methods described for assigning a date to an inscription at the experimental level, about 40 known authentic Tamil inscriptions, from the period AD 901 to 1500, are chosen. About 314 features are selected, most of which are found in the samples. The six centuries are split into 12 periods of 50 years each. The first period corresponds to AD 901-950 or earlier, the second period to AD 951-1000 and so on (Table 1). The feature vector of a period is obtained from the samples representing that period. A feature is reckoned to be present in a period if it is present in at least one of the inscriptions belonging to that period. A sample set of features is shown in Fig. 2. In the present experiment the values of M and N are 40 and 314 respectively.
Table 1
List of periods
| Periods |
Years |
| 1 | 901 AD- 950 AD |
| 2 | 951 AD-1000 AD |
| 3 | 1001 AD-1050 AD |
| 4 | 1051 AD-1100 AD |
| 5 | 1101 AD-1150 AD |
| 6 | 1151 AD-1200 AD |
| 7 | 1201 AD-1250 AD |
| 8 | 1251 AD-1300 AD |
| 9 | 1301 AD-1350 AD |
| 10 | 1351 AD-1400 AD |
| 11 | 1401 AD-1450 AD |
| 12 | 1451 AD-1500 AD |
Each sample inscription is converted into a vector of 314 positions with each position having values 1 or 0, depending upon the presence or absence of the corresponding feature. The feature vectors of all inscriptions form the library.
To test the robustness of the proposed method, a known authentic inscription of King Kulothunga III (AD 1178-1216), belonging to his fifteenth regnal year and found on the temple wall at Tirukkacchur near Madras, is considered first. The inscription is converted into a vector of 314 positions, with the presence or absence of features indicated by 1or 0, and comparisons are made with the library inscriptions. Both the direct and the weighted comparison methods assign this inscription correctly to the second half of the twelfth century.
Next, as a test inscription, one of unknown authorship belonging to a king with the title Tribhuvana Chakravarti Ko$ne$rinmai Konda$n is chosen. This inscription is found on the Devi Shrine of the Brihadiswarar temple at Tanjavur (Hultzsch, 1892). The title was borne by many kings, including Kulotunga III. Sivaramamurthy (1960) attributes the inscription to a king of the Pandya dynasty of the thirteenth century. It is well known that the Pandya power was felt in the Chola country only during the latter half of the thirteenth century after the period of Kulotunga III. We are therefore interested in knowing whether the inscription belongs to the first or the second half of the thirteenth century.
The test inscription is also converted into a feature vector. Using the direct comparison method described in Section IV, the result is obtained as "THE GIVEN PIECE OF INSCRIPTION IS CLOSE TO THE KNOWN INSCRIPTION NO. 33 WHICH BELONGS TO THE PERIOD 1251 AD TO 1300 AD." Even with the weighted comparison method, using methods A and B, the verdict of the computer is the same. This verdict supports Sivaramamurthy's claim.
Table 2
Feature vectors of periods based on sample features in Fig. 2
| Features |
Periods | ||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | T* | |
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| 5 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
| 9 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 11 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 12 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 13 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 14 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 15 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 16 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 |
| 17 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 18 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 19 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 20 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 21 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 22 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 23 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 24 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 25 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 26 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 27 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 |
| 28 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 29 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 30 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 31 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 32 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 33 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 34 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 35 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 36 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 37 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 38 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 39 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 40 | 0 | 0 | 0 | 1 | 1. | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
An attempt is also made to compare the features of the test inscriptions with those of the periods. The twelve feature vectors of the periods constitute the library. Feature vectors of the periods with respect to the 40 features listed in Fig. 2 are given in Table 2. Both the direct and the weighted comparison methods are tried and the results conform to the earlier verdict of the computer.
8. Feature reduction
Instead of making the comparison only once by considering all the 314 features, one can study the discriminatory power of the features by considering those that occur in no more than R ( < P ) periods. Thus in the experiment, the direct comparison method is followed with varying R. When R = 1, those features which occur in only one period out of the 12 periods are considered. Similarly, if R = 2, the features which occur in only one or two periods will be used in the comparison. Since the features which occur in all twelve periods will not have any discriminating capacity and therefore are discarded, the value of R cannot exceed 11.
The features of the test inscription can be compared with those of periods as well as individual samples. First, we consider comparisons with period characteristics.
The similarity measure for direct comparison is tried with R varying from 1 to 11. In this case, the summation of the similarity function is extended only to those features for which the condition on R is satisfied. In Table 3, the similarity values of the test inscription with the library are shown for various values of R. The periods to which the test inscription is assigned are indicated by asterisks. It is clear from the table that the consistency in the assignment is attained only for those values of R greater than 3.
It is also noted that the similarity values remain constant for R greater than 7 because the features present in the test vector are all exhausted when R takes the value 8. Hence, addition of features in the comparison does not contribute to the similarity values.
Table 3
Similarity values obtained by direct comparison of test inscription with periods
by varying the number of features on
the basis of R
| S.No. Periods (AD) |
Values of R | |||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | ||
| 1. | 901-950 | 0 | 1 | 1 | 2 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 2. | 951-1000 | 0 | 3* | 4* | 5 | 8 | 9 | 9 | 9 | 9 | 9 | 9 |
| 3. | 1001-1050 | 2* | 3* | 3 | 5 | 6 | 7 | 7 | 9 | 9 | 9 | 9 |
| 4. | 1051-1100 | 0 | 2 | 4* | 9 | 14 | 16 | 16 | 18 | 18 | 18 | 18 |
| 5. | 1101-1150 | 0 | 0 | 1 | 3 | 4 | 4 | 4 | 5 | 5 | 5 | 5 |
| 6. | 1151-1200 | 0 | 0 | 0 | 2 | 4 | 5 | 5 | 7 | 7 | 7 | 7 |
| 7. | 1201-1250 | 1 | 1 | 1 | 2 | 3 | 4 | 4 | 5 | 5 | 5 | 5 |
| 8. | 1251-1300 | 0 | 2 | 3 | 10* | 16* | 18* | 18* | 20* | 20* | 20* | 20* |
| 9. | 1301-1350 | 0 | 2 | 4 | 5 | 10 | 12 | 12 | 14 | 14 | 14 | 14 |
| 10. | 1351-1400 | 0 | 0 | 1 | 2 | 7 | 8 | 8 | 9 | 9 | 9 | 9 |
| 11. | 1401-1450 | 0 | 1 | 1 | 2 | 5 | 6 | 6 | 8 | 8 | 8 | 8 |
| 12. | 1451-1500 | 0 | 0 | 0 | 2 | 3 | 3 | 3 | 4 | 4 | 4 | 4 |
Method A is used to obtain similarity values by giving weights to the features depending upon the value of R. The features that are used in the comparison are controlled by the value of R with the corresponding weight assigned by method A. For a fixed R, the weights range from 1 to R. Table 4 presents the details of similarity values giving weights to the features for various values R. Even though the assignment of period fluctuates for the initial values of R, it remains constant for those values of R greater than 4.
Method B is based on the diadic logarithm of the number of occurrences of features over the periods. For features occurring in no more than 2K periods, the weight will range from 1 to K. Since there are only twelve periods, the maximum value of K cannot exceed four. Thus we get four possible assignments of weight, for each of which similarity values have been calculated. The weighted similarity values are given in Table 5. It is observed that the correct assignment is achieved when K takes the values 3 and 4.
The direct comparison and the weighted comparison methods are also attempted with individual samples for various values of R and K. It is noted that the assignment of the test inscription to the sample inscription 33 agrees with the assignment to the latter half of the thirteenth century. It is observed that the correct assignments remain the same, for period-wise and sample-wise comparisons.
The consistency in assigning date to an inscription has thrown some light on the possibilities of feature reduction. One should not, however, bring down the number of features drastically, as those which occur in fewer periods do not assign the correct date because the individual period characteristics are not found in the test inscriptions. Hence, it is to be noted that the assignment of date to an inscription depends not only on the library features but also on the availability of the features in the test inscription. Thus, in order to maintain an optimum number of comparisons it is necessary to retain some features which occur in a larger number of periods.
Table 4
Similarity values obtained by weighted comparison of test inscription with periods
by varying the number of features on the basis of R: Method A
| S.No. Periods (AD) |
Values of R | |||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | ||
| 1. | 901-950 | 0 | 1 | 2 | 4 | 8 | 12 | 16 | 20 | 24 | 28 | 32 |
| 2. | 951-1000 | 0 | 3 | 7 | 12 | 20 | 29 | 38 | 47 | 56 | 65 | 74 |
| 3. | 1001-1050 | 2* | 5* | 8* | 13 | 19 | 26 | 33 | 42 | 51 | 60 | 69 |
| 4. | 1051-1100 | 0 | 2 | 6 | 15* | 29 | 45 | 61 | 79 | 97 | 115 | 133 |
| 5. | 1101-1150 | 0 | 0 | 1 | 4 | 8 | 12 | 16 | 21 | 26 | 31 | 36 |
| 6. | 1151-1200 | 0 | 0 | 0 | 2 | 6 | 11 | 16 | 13 | 30 | 37 | 44 |
| 7. | 1201-1250 | 1 | 2 | 3 | 5 | 8 | 12 | 16 | 21 | 26 | 31 | 36 |
| 8. | 1251-1300 | 0 | 2 | 5 | 15* | 31* | 49* | 67* | 87* | 107* | 127* | 147* |
| 9. | 1301-1350 | 0 | 2 | 4 | 9 | 19 | 31 | 43 | 57 | 71 | 85 | 99 |
| 10. | 1351-1400 | 0 | 0 | 1 | 3 | 10 | 18 | 26 | 35 | 44 | 53 | 62 |
| 11. | 1401-1450 | 0 | 1 | 2 | 4 | 9 | 15 | 21 | 29 | 37 | 45 | 53 |
| 12. | 1451-1500 | 0 | 0 | 0 | 2 | 5 | 8 | 11 | 15 | 19 | 23 | 27 |
Table 5
Similarity values obtained by weighted comparison of test inscription with
periods
by varying the number of features on the basis of A": Method B Values of K
| S.No.Periods (AD) | Values of K | ||||
| 1 | 2 | 3 | 4 | ||
| 1. | 901-950 | 0 | 1 | 5 | 9 |
| 2. | 951-1000 | 0 | 4 | 13 | 22 |
| 3. | 1001-1050 | 2* | 5* | 12 | 21 |
| 4. | 1051-1100 | 0 | 4 | 20 | 38 |
| 5. | 1101-1150 | 0 | 1 | 5 | 10 |
| 6. | 1151-1200 | 0 | 0 | 5 | 12 |
| 7. | 1201-1250 | 1 | 7 | 6 | 11 |
| 8. | 1251-1300 | 0 | 3 | 21* | 41* |
| 9. | 1301-1350 | 0 | 2 | 14 | 28 |
| 10. | 1351-1400 | 0 | 1 | 9 | 18 |
| 11. | 1401-1450 | 0 | 1 | 7 | 15 |
| 12. | 1451-1500 | 0 | 0 | 3 | 7 |
9. Fuzzy set theoretic approach
The problem can also be viewed from the standpoint of fuzzy set theory (Zadeh, 1965; Dutta Majumder and Pal, 1976). An appropriate fuzzy membership function can be defined to assign weights to the features as follows :
If Wij denotes the membership value of the jth feature to the
ith period, then
Wij = 1 (S-1) / R if S <or=R <P,
0 otherwise
where P, R and S are the same as in Section 5. It follows from the definition that if a feature is present in only one period, then the membership value for that feature will be 1. If it is present in more than R periods, the membership value of that feature will be 0; otherwise, the values lie between 0 and 1.
The membership function, defined here, provides an alternative method of assigning weights to the features. It is similar to the function W1j used for the assignment of weights in method A. In the same way, a membership function similar to the function used in method B can be defined.
It is clear from the definition that if this membership function is used, the assignment of the test inscription to a period by the weighted comparison method will not be altered. We have thus indicated that the problem of dating an inscription can be converted to the one in fuzzy set theory.
In the Appendix we describe the well known similarity measures such as Jaccard and Simple Matching coefficients in addition to the direct and weighted comparison methods introduced by us. Modifications of the above methods are also proposed.
Similarity measures discussed in the Appendix were also used for assigning dates and it was found that the Simple Matching coefficients S.2 and the Modified Simple Matching coefficient W.2 did not assign correct dates to the two test inscriptions. However, the Jaccard coefficients S.I and the Modified Jaccard coefficient W.I assigned correct dates to the test inscriptions and the results agree with the dates assigned by the proposed methods.
The methods proposed by us are simple and intuitively preferable to the earlier methods for assigning dates to inscriptions.
10. Writer identificationAn application
The method used in the dating of medieval Tamil inscriptions can be directly applied to the problem of assigning passage of Tamil handwriting to one of the M writers whose handwriting characteristics are known. Here the set of features in the handwriting corresponds to the set of features extracted from the medieval Tamil inscriptions. The handwriting of the M writers would correspond to the library inscriptions, and a test passage in modern Tamil script whose authorship is to be found would correspond to the test inscription.
In an experiment, using Tamil passages written by forty different writers, about 117 features were considered. Six test passages were also written by six of the forty writers. With the methods developed for dating inscriptions, a hundred percent recognition rate was achieved (Siromoney, Chandrasekaran and Chandrasekaran, 1984).
We have also made an attempt to find out how successful an observer would be in identifying the writer. About 108 subjects were given the test passages and asked to match them with the forty samples of handwriting. Only fifty-four subjects were able to identify the writers correctly. The computer methods are thus shown to be more powerful than human observation in identifying writers.
11. Conclusion
The computer methods proposed for assigning dates to inscriptions of unknown authorship are quite general and could be applied to writings of any period in any language. First, samples of authentic inscriptions of different periods are collected. Then each inscription is converted into numerical form on the basis of the letters found in it, either part of a letter, or the whole letter. The features could be treated as equally important, or alternatively, some of them could be assigned greater weight. A given inscription of unknown authorship is converted to numerical form in accordance with the presence of various features. Then the comparisons are made with the authentic inscriptions and the unknown piece of inscription is assigned to a suitable period on the basis of the proposed similarity measures.
Another method is to work with the period characteristics, obtained from the features of the samples belonging to each period. Instead of being made with the samples, the comparisons are made with the period characteristics. By making use of the similarity measures, a given inscription of unknown authorship could be assigned to a suitable period.
Two inscriptions are chosen as tests and comparisons are made with the sample as well as the period characteristics. The inscriptions are assigned to the correct periods by the computer.
Acknowledgement
The authors wish to thank the Department of Science and Technology, Government of India, for financial
assistance.
Following the same terminology as in Section 3 for Li j, Tj, M and N, we define some similarity coefficients as follows.
Characteristic function. For any two values a and b the characteristic function is defined as,
I(a,
b) = 1 if a = b, 0 if a is not equal to b.
We define a function x corresponding to matched and unmatched pairs of features of the test inscription with the
ith library inscription as,
xrs(i) =
j
= 1 to N![]() I(Li j, r) X I(Tj, s) where
r, s belong to {0, 1}, i =1,2,...,M
I(Li j, r) X I(Tj, s) where
r, s belong to {0, 1}, i =1,2,...,M
Similarity coefficients
S. 1. Jaccard coefficient:
Ji = x11(i) / ( x11(i) +
x10(i) + x01(i) )
S.2. Simple matching coefficient:
Si = ( x11(i) + x00(i)) / (x11(i)
+ x10(i) + x01(i) + x00(i)
)
S.3. Direct comparison function:
Di = x11(i)
We denote the weight assigned to jth feature by Wj and define a function
w as follows.
wrs(i) = j = 1 to N![]() Wj
X I(Li j, r) X I(Tj,s)
Wj
X I(Li j, r) X I(Tj,s)
where
r, s belong to {0,1}.
Proposed weighted similarity coefficients
W.1. Modified Jaccard coefficient
:
MJi = w11(i) / ( (w11(i) +
w10(i)
+ w01(i) )
W.2. Modified simple matching coefficient:
MSi = ( w11(i) + w00(i) )
/ ( (w11(i) + w10(i) + w01(i) +
w00(i) )
W.3. Weighted comparison function:
MDi = w11(i)
If one wishes to use the normalized forms of S.3 and W.3, the following values could be used as divisors. For S.3 the divisor is DR and for W.3 it is WDR where